架构
在最高层级别上,一个pulsar实例由一个或多个pulsar cluster组成。集群中的实例可以在它们之间复制数据。
Pulsar 集群包含:
- 一个或多个broker处理并平衡来自生产者的传入消息,将消息分发给消费者,与Pulsar配置存储通信以处理各种协调任务,将消息存储在BookKeeper实例中(又名bookies),依赖集群特定的ZooKeeper集群来完成某些任务,等等。
- 由一个或多个bookies组成的BookKeeper集群处理消息的持久存储。
- 一个特定于该集群的ZooKeeper集群处理Pulsar集群之间的协调任务。
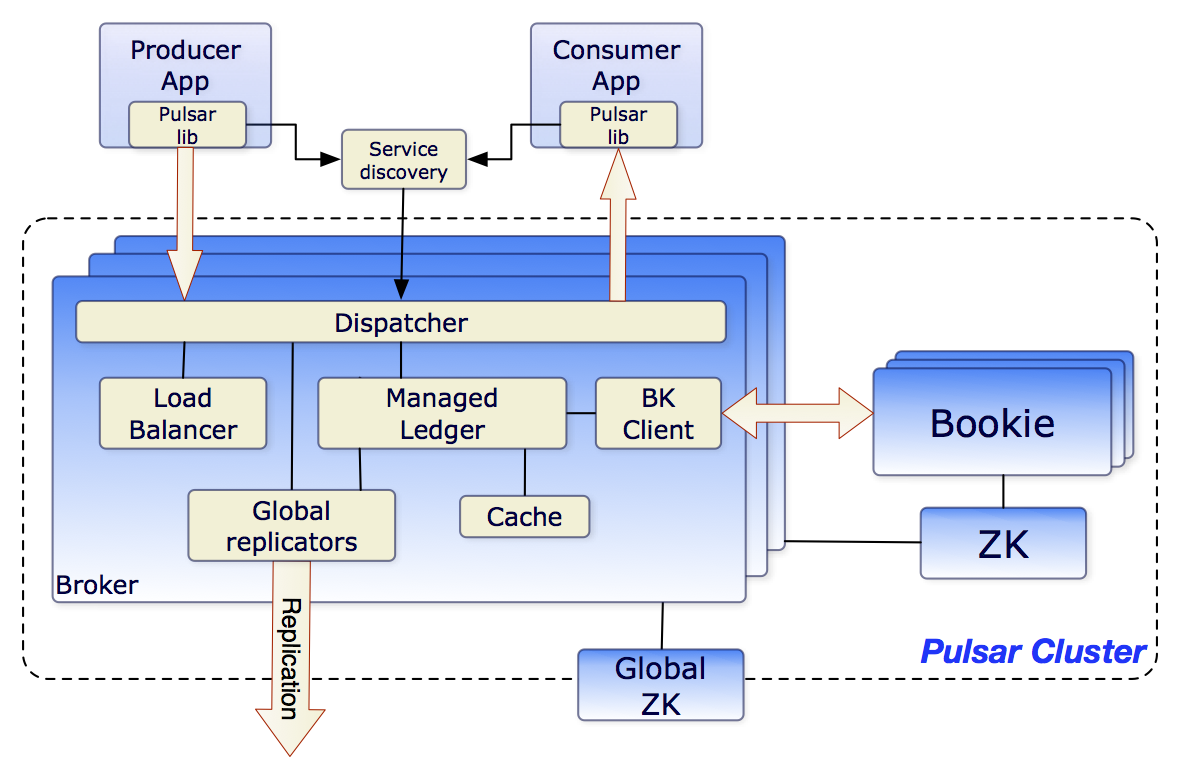
在更广的维度上,称为配置存储的实例级ZooKeeper集群处理涉及多个集群的协调任务,用途是多地域的灾备复制。
brokers
Pulsar Brokers是一个无状态组件,主要负责运行其他两个组件:
- 一个HTTP服务器,它为生产者和消费者的管理任务和主题查找公开一个REST API。生产者连接到代理来发布消息,消费者连接到代理来使用消息。
- 调度程序,它是一个异步TCP服务器,使用自定义二进制协议进行所有数据传输
为了提高性能,消息通常从managed ledger缓存分发出去,除非积压超过缓存大小。如果积压的内容对于缓存来说太大,Brokers将开始从BookKeeper读取条目。
最后,为了支持全局主题上的geo-replication,代理管理复制器,这些复制器跟踪本地区域中发布的条目,并使用Pulsar Java客户端库将它们重新发布到远程区域。
集群
一个Pulsar实例由一个或多个Pulsar cluster组成。集群依次包括:
- 一个或多个Brokers
- 用于集群级配置和协调的ZooKeeper仲裁
- 用于持久存储消息的一组bookies
集群可以使用地理复制在彼此之间进行复制。
元数据存储
Pulsar元数据存储维护一个Pulsar集群的所有元数据,例如主题元数据、模式、代理加载数据,等等。Pulsar使用Apache ZooKeeper进行元数据存储、集群配置和协调。Pulsar元数据存储可以部署在单独的ZooKeeper集群上,也可以部署在已有的ZooKeeper集群上。你可以使用一个ZooKeeper集群来存储Pulsar元数据和BookKeeper元数据。如果你想部署连接到现有BookKeeper集群的Pulsar代理,你需要为Pulsar元数据存储和存储部署单独的ZooKeeper集群
Info
Pulsar还支持更多的元数据后端服务,包括ETCD和RocksDB(仅供Pulsar独立使用)。
在Pulsar实例中:
- 配置存储仲裁存储需要全局一致的租户、名称空间和其他实体的配置。
- 每个集群都有自己的本地ZooKeeper集成存储特定于集群的配置和协调,比如哪个代理负责哪个主题、所有权元数据、代理加载报告、BookKeeper分类账元数据等等。
配置存储
配置存储维护一个Pulsar实例的所有配置,例如集群、租户、名称空间、与分区主题相关的配置,等等。一个Pulsar实例可以有一个本地集群、多个本地集群或多个跨区域集群。因此,配置存储可以跨Pulsar实例下的多个集群共享配置。配置存储可以单独部署在一个ZooKeeper集群上,也可以部署在已有的ZooKeeper集群上。
持久存储
Pulsar为应用程序提供有保证的消息传递。如果消息成功到达Pulsar Brokers,它将被发送到预定目标。
这种保证要求以持久的方式存储未被确认的消息,直到它们可以交付给消费者并被消费者确认为止。
Apache BookKeeper
Pulsar使用一个名为Apache BookKeeper的系统进行持久消息存储。BookKeeper是一个分布式的预写日志(WAL)系统,为Pulsar提供了许多关键的优势:
- 它使Pulsar能够利用许多独立的日志,称为
ledgers。随着时间的推移,可以为主题创建多个ledgers。 - 它为处理条目复制的序列数据提供了非常有效的存储。
- 它保证在出现各种系统故障时
ledgers的读取一致性。 - 它为Brokers提供了均匀分布的I/O。
- 它在容量和吞吐量方面都是水平可伸缩的。通过向集群中添加更多的bookies,可以立即增加容量。
- Bookies设计用于处理数千个账本,同时进行读写操作。
除了消息数据之外,游标也持久化存储在BookKeeper中。游标是使用者的订阅位置。BookKeeper使Pulsar以可伸缩的方式存储消费者的位置。
概念:
- Bookie:BookKeeper 的一部分,处理需要持久化的数据。
- Ledger:BookKeeper 的存储逻辑单元,可用于追加写数据。
- Entry:写入 BookKeeper 的数据实体。当批量生产时,Entry 为多条消息,当非批量生产时,Entry 为单条数据。
Bundle
我们知道, Topic 分区会散落在不同的 Broker 中,那 Topic 分区和 Broker 的关系是如何维护的呢?当某个 Broker 负载过高时, Pulsar 怎么处理呢?
Topic 分区与 Broker 的关联是通过 Bundle 机制进行管理的。
每个 namespace 存在一个 Bundle 列表,在 namesapce 创建时可以指定 Bundle 的数量。Bundle 其实是一个分片机制,每个 Bundle 拥有 namespace 整个 hash 范围的一部分。每个 Topic (分区) 通过 hash 运算落到相应的 Bundle 区间,进而找到当前区间关联的 Broker 。每个 Bundle 绑定唯一的一个 Broker ,但一个 Broker 可以有多个 Bundle 。
如下图,T1、T2 这两个 Topic 的 hash 结果落在[0x0000000L——0x4000000L]中,这个 hash 范围的 Bundle 对应 Broker 2, Broker 2 会对 T1、T2 进行处理。
同理,T4 的 hash 结果落在[0x4000000L——0x8000000L]中,这个 hash 范围的 Bundle 对应 Broker 1, Broker 1 会对 T4 进行处理;
T5 的 hash 结果落在[0x8000000L——0xC000000L]中,这个 hash 范围的 Bundle 对应 Broker 3, Broker 3 会对 T5 进行处理;
T3 的 hash 结果落在[0xC000000L——0x0000000L]中,这个 hash 范围的 Bundle 对应 Broker 3, Broker 3 会对 T3 进行处理。
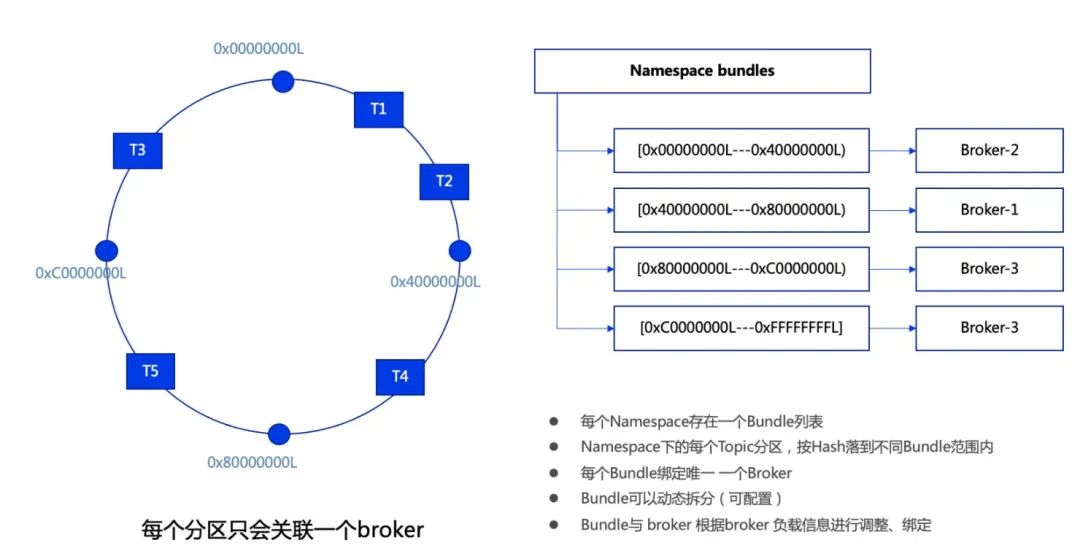
Bundle 可以根据绑定的 Broker 的负载进行动态的调整、绑定。当 Bundle 绑定的 Broker 的 Topic 数过多、负载过高时,都会触发 Bundle 拆分,将原有的 Bundle 拆分成 2 个 Bundle ,并将其中一个 Bundle 重新分配给不同的 Broker ,以降低原 Broker 的 Topic 数或负载。
分片存储
Pulsar 在物理上采用分片存储的模式,存储粒度比分区更细化、存储负载更均衡。如图,一个分区 Topic-Partition 2 的数据由多个分片组成。每个分片作为 BookKeeper 中的一个 Ledger ,均匀的分布并存储在 BookKeeper 的多个 Bookie 节点中。
基于分配存储的机制,使得 Bookie 的扩容可以即时完成,无需任何数据复制或者迁移。当 Bookie 扩容时,Broker 可以立刻发现并感知新的 Bookie ,并尝试将新的分片 Segment 写入新增加的 Bookie 中。
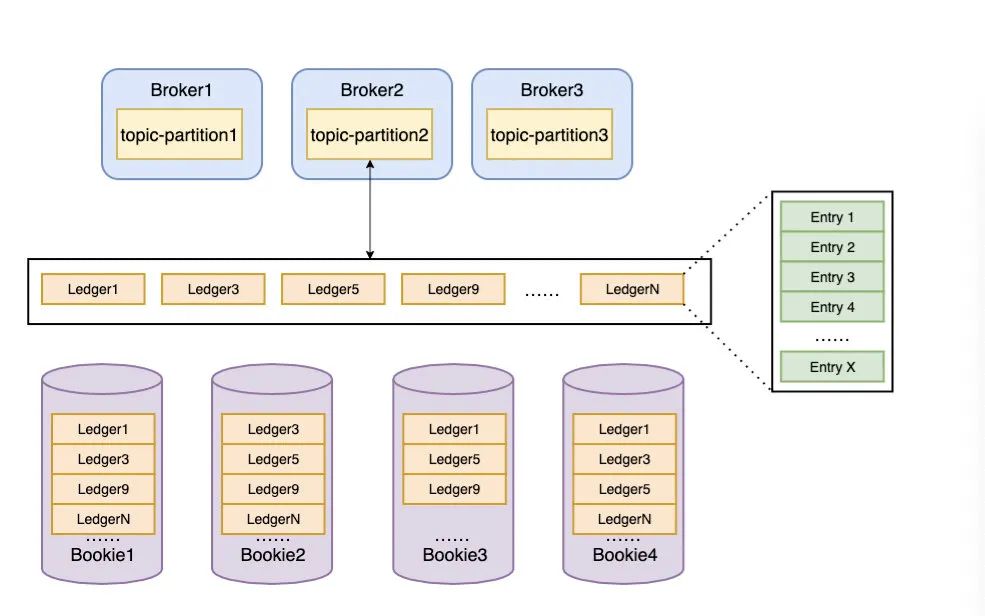
如上图,在 Broker 中,消息以 Entry 的形式追加的形式写入 Ledger 中,每个 Topic 分区都有多个非连续 ID 的 Ledger,Topic 分区的 Ledger 同一时刻只有一个处于可写状态。
Topic 分区在存储消息时,会先找到当前使用的 Ledger ,生成 Entry ID(每个 Entry ID 在同一个 Ledger 内是递增的)。当 Ledger 的长度或 Entry 个数超过阈值时,新消息会存储到新 Ledger 中。每个 messageID 由[Ledger ID, Entry ID, Partition 编号,batch-index]组成。( Partition :消息所属的 Topic 分区,batch-index:是否为批量消息)
一个 Ledger 会根据 Topic 指定的副本数量存储到多个 Bookie 中。一个 Bookie 可以存放多个不连续的 Ledger。